統計基礎工具說明
統計基礎工具 幫助使用者正確的運用檢定來比較平均值及比例。
比較平均值及比例,是分析最常使用,也是最基礎的統計檢定。但是錯誤的運用檢定方法,會得到錯誤的結果,反而誤導了決策。例如,two-sample t-test 常用來比較兩組數據的平均。但要注意的是,t-test 假設兩組數據的分佈是近似常態,因此應用 t-test 時必須要確認數據分佈是否為常態。非常態分佈的數據,如果樣本數够大,依據中央極限定理,平均值的分佈會接近常態,在這種狀況下,也是可以使用 t-test。此外,離群值會降低判斷出平均值有差異的機率,因此檢驗數據中的離群值是否合理,也是做檢定的重要步驟。所以並不是拿到數據,就直接做 t-test,然後看 p-value 來決定平均值或比例有沒有差異,而是要仔細的檢視數據的型態,有無 outlier,數據是否有異常,再運用適合檢定方法。
在這個應用程式中,我們將檢視離群值及常態分佈整合至比較平均值或比例的檢定過程中,加上圖表的視覺化輔助,幫助使用者正確的比較平均或比例的差異。讀者可以參應用說明,以自己的資料進行更完整的平均值或比例檢定。
一、簡介:
統計基礎工具的應用介面包含三個功能:
- Review and Clean Data:檢查數據中是否有重複的資料列,是否有遺失值及極端值。以及對數據做總結及檢視數據分佈。
- Comparing Mean:比較平均值,包括 one-sample, two-sample 及 paired-sample。
- Comparing Proportion:比較比例,包括 one-proportion, two-proportion 及 paired-proportion。
二、使用內建數據
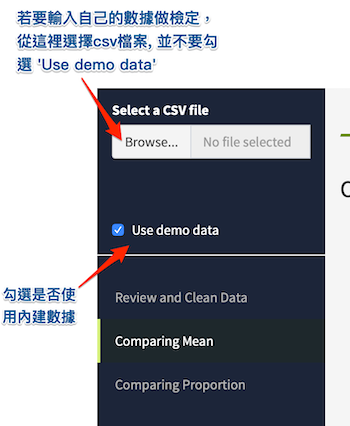
應用程式中含有內建的數據,使用者可以使用內建的數據測試及了解介面功能。使用內建數據,勾選左側側邊欄的 ‘Use demo data’ 即可。如果要使用自己的數據,記得不要勾選這個選項。
三、使用 Review and Clean Data
使用者可以利用這個介面功能檢查數據中:是否有重複的資料列、是否有遺失值及極端值,以及對數據做總結及檢視數據分佈。

四、使用 Comparing Mean
這個介面用於比較平均值是否有差異,包括 one-sample, two-sample 及 paired-sample。
輸入數據
數據內容先用試算表(例如 excel 或 google sheet) 輸入數據再儲存成 csv 格式。再利用側邊欄的 ‘Select a CSV file’ 選擇要分析的 csv 檔。
數據格式: csv 檔的第一列為欄位名稱,數據從第二列開始。
- 單一樣本群組 (one-sample):將數據放在第一欄。

- 兩組樣本群組 (two-sample 及 paired-sample):包含三個欄位。第一個欄位為每個樣本的 id,每一列為一個樣本, id 不可重複,若無特定 id, 編上流水號也可以。第二欄為樣本的群組別。第三欄為樣本的值,因為是 two-sample,所以應只有兩個群組別。欄位順序可以互換,在介面中,會選擇 id, 樣本值跟群組別相對應的欄位。

使用介面
選擇檔案後,選擇資料對應的欄位。再選擇要設定的 null hypothesis,之後按照比較平均值的檢定需求(通常是考量型一及型二風險)設定檢定的顯著水準(significance level, 通常被簡稱為 alpha)。所有參數設定完成之後,按 ‘SUBMIT’ 執行檢定運算。
比較平均值一般狀況下會用 t-test,但是若數據分佈型態明顯偏離 t-test 的假設條件,使用非參數式的檢定會比較合適。
使用者可以選擇 auto 讓程式自動運算合適的檢定方法,也可以自行選擇。不論是 auto 或是自行選擇,介面都會帶出相關的數據型態檢查結果,像離群值及常態分佈的檢驗。

自動檢查離群值及常態分佈,並產生圖形輔助分析

t-test 的結果輸出
由於 t-test 會產生較多的有用資訊,若數據型態不符合使用 t-test,儘量檢查數據的內容,看看是否含有錯誤的數據。

若數據中含有嚴重離群值,最好是檢查數據的正確性或者與檢定目的的相關性。貿然去除離群值是不科學的做法,但若不仔細檢查離群值的可靠性,則會增加型二的風險,亦即,可能平均值已有差異,但檢定結果卻無法判別出來。如數據分佈型態偏離常態分佈,試著用 log 或 box-cox 先轉換數據。
如果數據型態不適合用 t-test,可使用無母數 (nonparametric) 檢定, 例如 Wilcoxon signed rank test

五、使用 Comparing Proportion
這個介面功能用於比較比例,包括 one-proportion, two-proportion 及 paired-proportion。
輸入數據
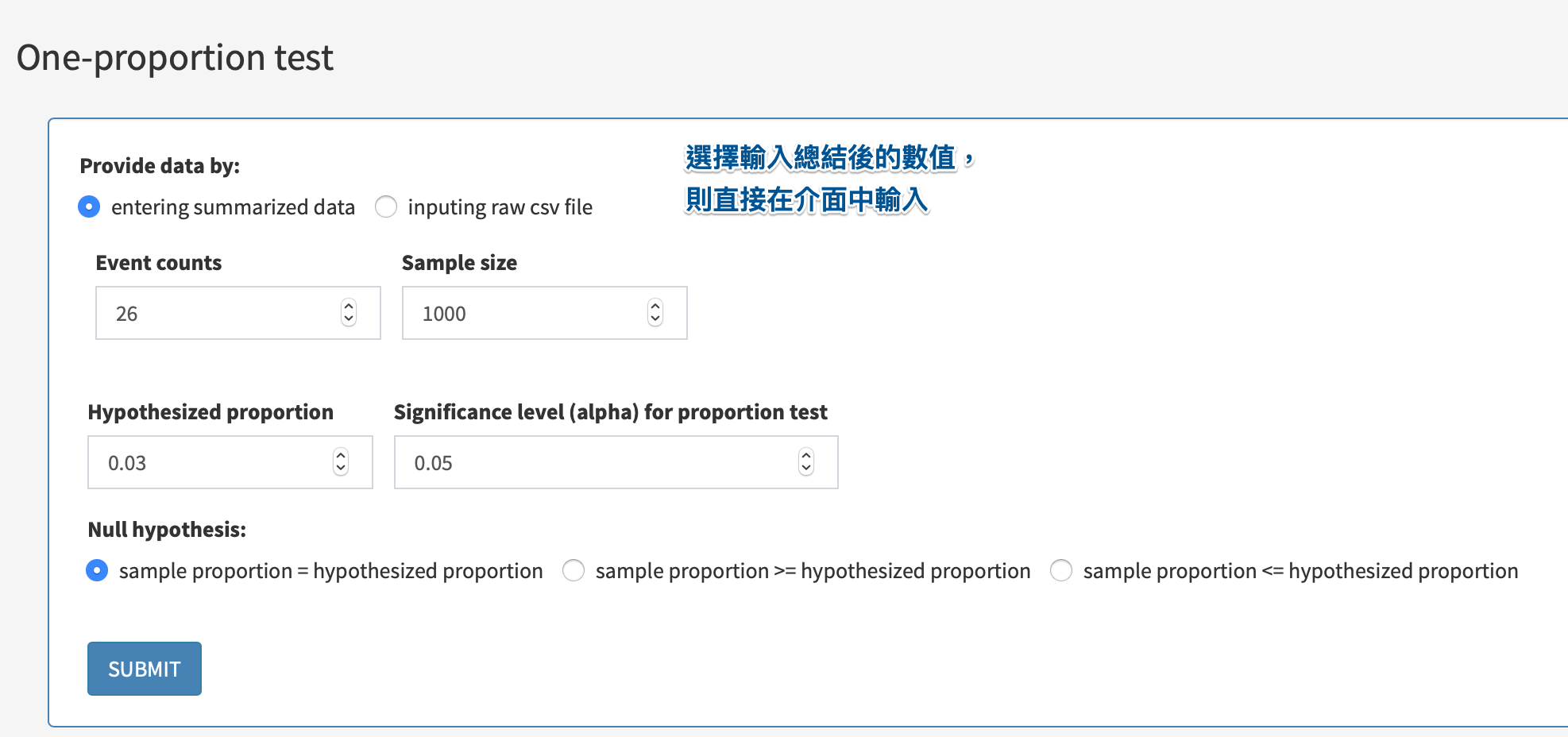
數據若是總結成總樣本數跟事件發生的總數,則直接在介面中輸入。
數據若是包含多個批次的批次資料,則依下列方式整理數據:(注意第一列為欄位名稱,數據從第二列開始)
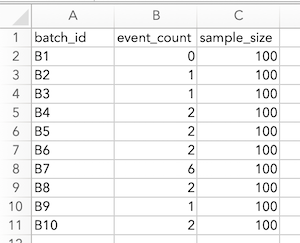
- 單一樣本群組(one-propprtion):將數據整理成三個欄位。第一欄為樣本的批次 id, 第二欄為該批次的 event count, 譬如檢查到的缺陷數目,第三欄為該批次的樣本數目。
- 兩組樣本群組(two-proportion 及 paired-proportion):除了上述的三個欄位外,再加上一欄樣本群組別。
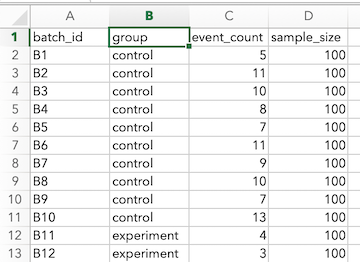
檔案中的欄位順序不重要,在應用介面中會選擇相對的欄位。
使用介面
數據輸入後,選擇要設定的 null hypothesis,再按照比較比例的檢定需求(通常是考量型一及型二風險)設定檢定的顯著水準(significance level, 通常被簡稱為 alpha)。所有參數設定完成之後,按 ‘SUBMIT’ 執行檢定運算。
(當樣本數太少,且事件發生比例極高或極低時,會使用 Fisher’s exact test 取代 proportion test。)
檢定結果輸出

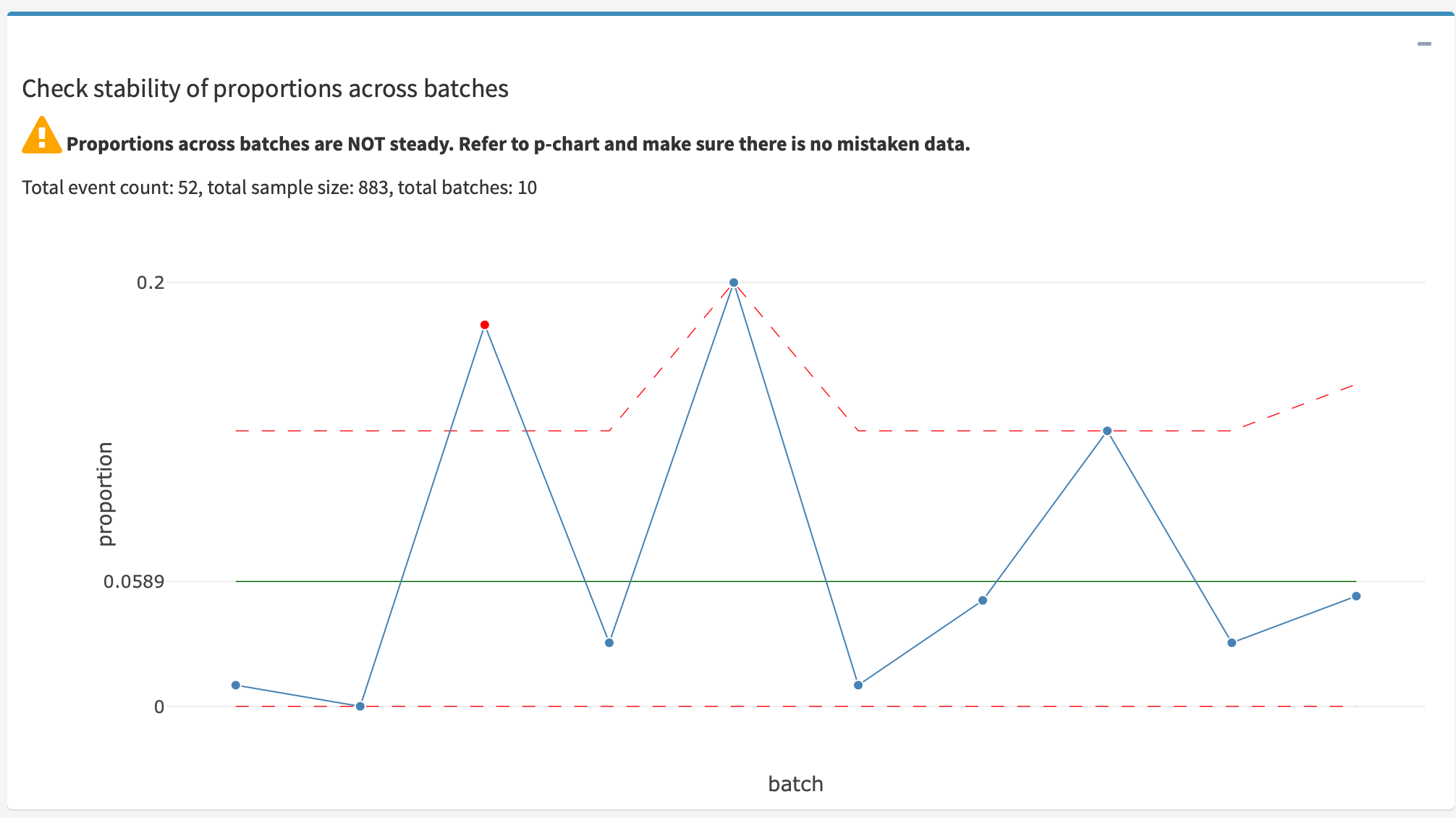
以 p-chart 檢驗批次的穩定性
若是選擇由檔案帶入樣批次的原始數據,程式會先用 p-chart 檢查 批次間的穩定性,若有不穩定的批次,務必要確認。
(注意!範例中 p-chart 的批次樣本數量並不一致,所以管制界限會隨樣本數量而變。)